

MCP简介
MCP(模型上下文协议,Model Context Protocol)由Anthropic 推出,旨在简化和标准化大型语言模型 (LLM) 与外部数据的交互方式,或者换一个简单点的说法,它定义了一个大模型怎样调用外部工具的范式。
我们知道,大模型生成内容的准确性一直是一个难题,尤其在一些时效性很强的问题上尤为严重,比如在不联网的情况下问大模型今天的天气的如何,大模型往往会胡乱编造一个答案或者直接回答不知道。不过换个角度想,哪怕是人,如果没有外界信息的输入,同样无法回答这样的问题。因此模型需要像人一样,通过外部工具来获取实时信息。不过,各个大模型框架调用工具的方式都不太一样,这就导致同一个工具在不同的环境下要进行重写,MCP就是为了解决这个问题而生,使得不同的大模型框架可以用相同的方式调用外部工具。
MCP可以分为以下3个部分:
MCP HOST: 可以简单理解为调用MCP的实体,比如各种大模型
MCP CLIENT: 向外部工具服务端发出调用请求的客户端
MCP SERVER:外部工具的服务端,包含外部工具是实现以及对客户端请求的响应
一般而言,MCP HOST 和 MCP CLIENT 基本都绑定在一起,所以整个MCP可以看作是客户端-服务端的架构。
在LangChain中使用MCP
这里以一个简单的谷歌搜索作为外部工具为例,当用户向大模型提出一些时效性很强的问题,比如现在北京的天气如何?大模型就会调用这个工具,将工具返回的结果进行整理后呈现给用户。
首先是MCP SERVER部分的实现:
import asyncio
from playwright.async_api import async_playwright
from playwright_stealth import stealth_async
import urllib.parse
from mcp.server.fastmcp import FastMCP
from openai import OpenAI
import base64
client = OpenAI(
base_url="https://ark.cn-beijing.volces.com/api/v3",
api_key="",
)
mcp = FastMCP()
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
def create_search_url(query, base_url="https://www.google.com/search?", language="zh-CN"):
"""
将查询字符串编码为 URL,并拼接成 Google 搜索 URL。
Args:
query (str): 要搜索的查询字符串。
base_url (str, optional): 搜索的基本 URL。默认为 "https://www.google.com/search?".
language (str, optional): 搜索结果的语言。默认为 "zh-CN" (简体中文).
Returns:
str: 完整的 Google 搜索 URL。
"""
encoded_query = urllib.parse.quote(query)
url = f"{base_url}q={encoded_query}&hl={language}"
return url
async def take_screenshot(url, output_path):
try:
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
)
await page.evaluate("document.charset = 'UTF-8';")
await page.evaluate('''
document.body.style.fontFamily = '"SimSun", "SimHei", sans-serif !important";';
''')
await stealth_async(page)
await page.goto(url)
await asyncio.sleep(2)
await page.screenshot(path=output_path, full_page=False)
await browser.close()
print(f"Screenshot saved to {output_path}")
except Exception as e:
print(f"An error occurred: {e}")
@mcp.tool()
async def google_search(query: str) -> str:
'''获取搜索信息'''
url = create_search_url(query)
await take_screenshot(url, 'screenshot.png')
image_path = '/home/ubuntu/python_projects/langchain_MCP/screenshot.png'
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="doubao-1-5-vision-pro-32k-250115",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "请获取图片中信息,并尽可能简短地描述"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{base64_image}",
},
},
],
}
],
)
print(response.choices[0].message.content)
return response.choices[0].message.content
if __name__ == "__main__":
mcp.run(transport="stdio")这里为了测试豆包视觉模型,所以我使用了一种很麻烦的方式来实现这个搜索功能。首先是将要搜索的内容进行URL编码,和谷歌搜索的baseurl拼接成完整的搜索链接,然后在浏览器中进行访问并截图,再把截图发给豆包视觉模型进行信息提取,然后把信息传给MCP CLIENT。
接着是MCP CLIENT部分的实现:
from langchain_openai.chat_models.base import BaseChatOpenAI
import asyncio
from langchain_mcp_adapters.tools import load_mcp_tools
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langgraph.prebuilt import create_react_agent
from langchain_core.messages import HumanMessage, AIMessage, ToolMessage
llm = BaseChatOpenAI(
model='deepseek-chat',
openai_api_key='',
openai_api_base='https://api.deepseek.com/v1',
max_tokens=1024
)
server_params = StdioServerParameters(
command="/home/ubuntu/python_projects/langchain_MCP/.micromamba/envs/default/bin/python",
args=["/home/ubuntu/python_projects/langchain_MCP/google_search.py"],
)
async def main():
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
await session.initialize()
tools = await load_mcp_tools(session)
agent = create_react_agent(llm, tools)
response = await agent.ainvoke({"messages": "今天北京的天气如何?"})
print(response['messages'][-1].content)
if __name__ == "__main__":
asyncio.run(main())
这一部分很简单,就是调用了一个大语言模型进行交互,只不过这次的交互过程中,通过StdioServerParameters告诉大模型怎么调用工具,如果大模型支持function call,则会根据工具信息选择合适的工具。
最后结果如下:

我们看看实际的搜索结果:
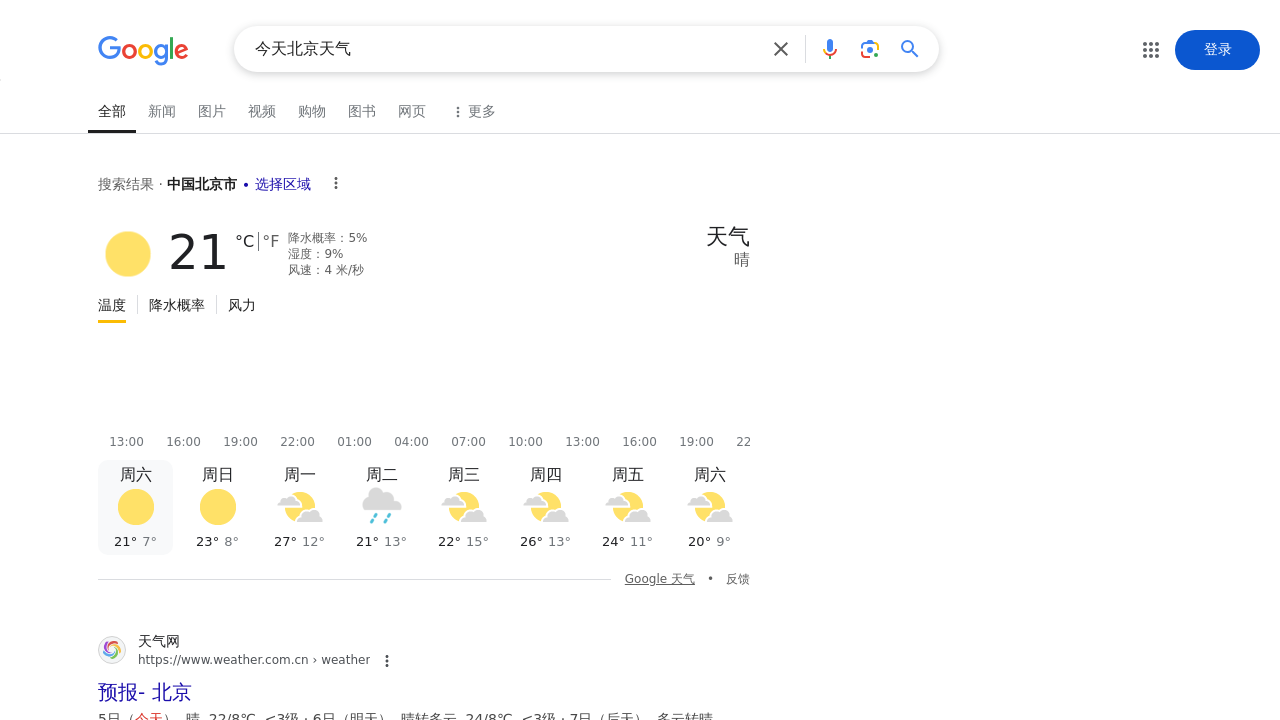
可以看到模型成功获取了正确的天气信息。
Comments